publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
-
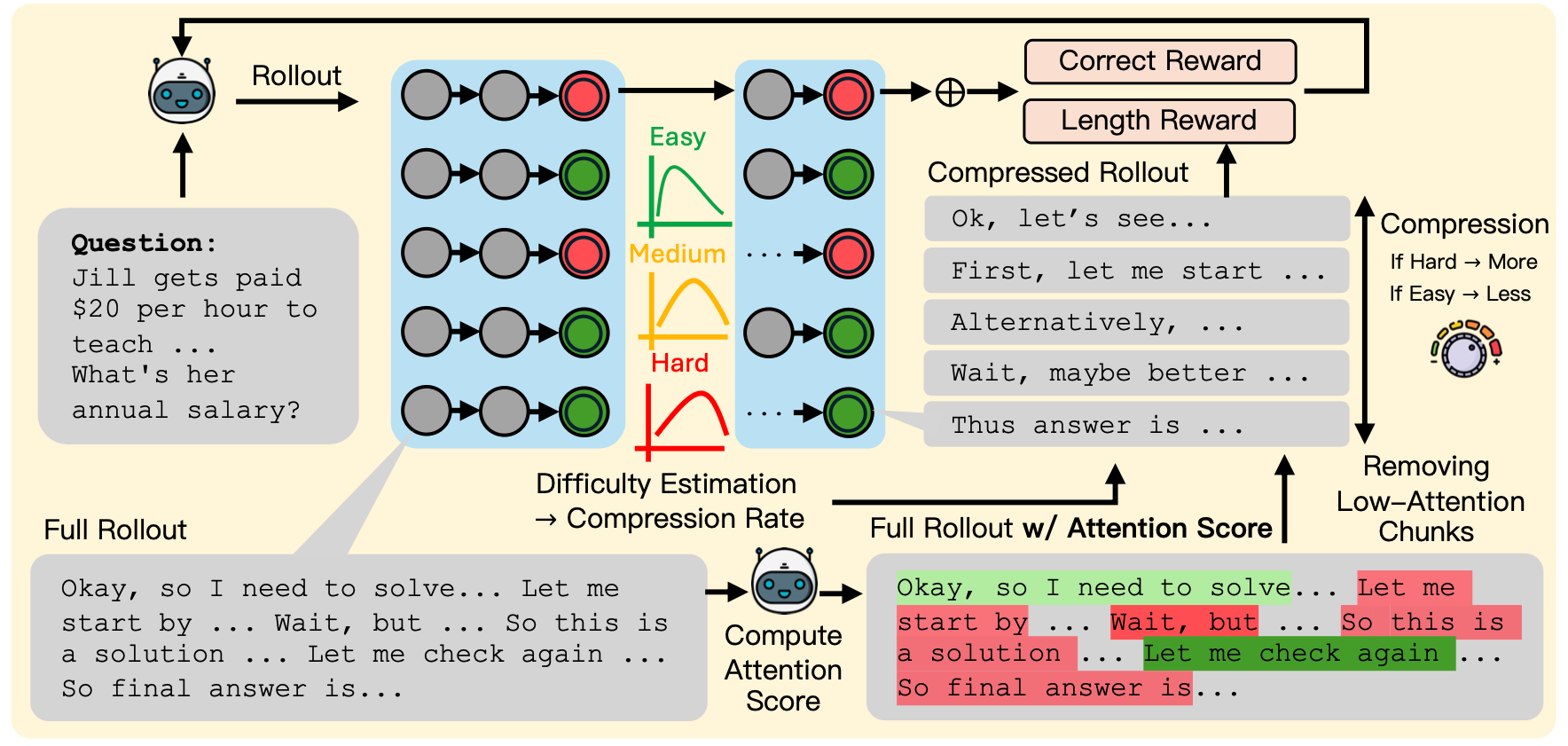 Think Right: Learning to Mitigate Under-Over Thinking via Adaptive, Attentive CompressionJoykirat Singh, Justin Chih-Yao Chen, Archiki Prasad, and 3 more authors2025
Think Right: Learning to Mitigate Under-Over Thinking via Adaptive, Attentive CompressionJoykirat Singh, Justin Chih-Yao Chen, Archiki Prasad, and 3 more authors2025Recent thinking models solve complex reasoning tasks by scaling test-time compute, but this scaling must be allocated in line with task difficulty. On one hand, short reasoning (underthinking) leads to errors on harder problems that require extended reasoning steps; but, excessively long reasoning (overthinking) can be token-inefficient, generating unnecessary steps even after reaching a correct intermediate solution. We refer to this as under-adaptivity, where the model fails to modulate its response length appropriately given problems of varying difficulty. To address under-adaptivity and strike a balance between under- and overthinking, we propose TRAAC (Think Right with Adaptive, Attentive Compression), an online post-training RL method that leverages the model’s self-attention over a long reasoning trajectory to identify important steps and prune redundant ones. TRAAC also estimates difficulty and incorporates it into training rewards, thereby learning to allocate reasoning budget commensurate with example difficulty. Our approach improves accuracy, reduces reasoning steps, and enables adaptive thinking compared to base models and other RL baselines. Across a variety of tasks (AIME, AMC, GPQA-D, BBEH), TRAAC (Qwen3-4B) achieves an average absolute accuracy gain of 8.4% with a relative reduction in reasoning length of 36.8% compared to the base model, and a 7.9% accuracy gain paired with a 29.4% length drop compared to the best RL baseline. TRAAC also shows strong generalization: although our models are trained on math datasets, they show accuracy and efficiency gains on out-of-distribution non-math datasets like GPQA-D, BBEH, and OptimalThinkingBench. Our analysis further verifies that TRAAC provides fine-grained adjustments to thinking budget based on difficulty and that a combination of task-difficulty calibration and attention-based compression yields gains across diverse tasks.
-
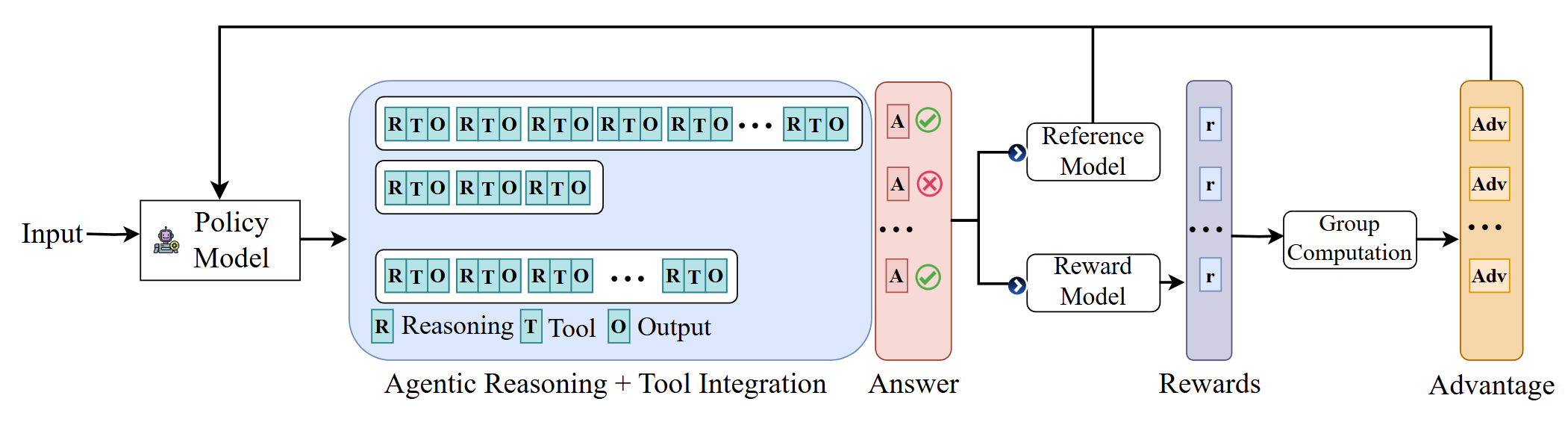 Agentic Reasoning and Tool Integration for LLMs via Reinforcement LearningJoykirat Singh, Raghav Magazine, Yash Pandya, and 1 more authorNeurIPS 2025 Workshop (FoRLM), 2025
Agentic Reasoning and Tool Integration for LLMs via Reinforcement LearningJoykirat Singh, Raghav Magazine, Yash Pandya, and 1 more authorNeurIPS 2025 Workshop (FoRLM), 2025Large language models (LLMs) have achieved remarkable progress in complex reasoning tasks, yet they remain fundamentally limited by their reliance on static internal knowledge and text-only reasoning. Real-world problem solving often demands dynamic, multi-step reasoning, adaptive decision making, and the ability to interact with external tools and environments. In this work, we introduce ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers), a unified framework that tightly couples agentic reasoning, reinforcement learning, and tool integration for LLMs. ARTIST enables models to autonomously decide when, how, and which tools to invoke within multi-turn reasoning chains, leveraging outcome-based RL to learn robust strategies for tool use and environment interaction without requiring step-level supervision. Extensive experiments on mathematical reasoning and multi-turn function calling benchmarks show that ARTIST consistently outperforms state-of-the-art baselines, with up to 22% absolute improvement over base models and strong gains on the most challenging tasks. Detailed studies and metric analyses reveal that agentic RL training leads to deeper reasoning, more effective tool use, and higher-quality solutions. Our results establish agentic RL with tool integration as a powerful new frontier for robust, interpretable, and generalizable problem-solving in LLMs.
-
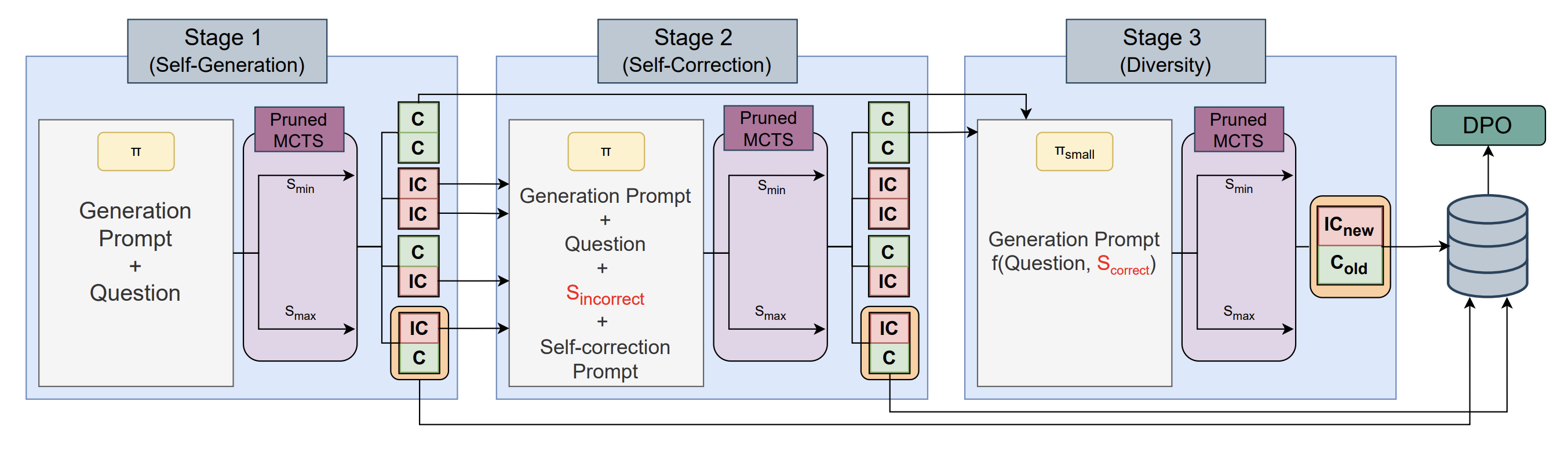 Self-Evolved Preference Optimization for Enhancing Mathematical Reasoning in Small Language ModelsJoykirat Singh, Tanmoy Chakraborty, and Akshay NambiPreprint, 2025
Self-Evolved Preference Optimization for Enhancing Mathematical Reasoning in Small Language ModelsJoykirat Singh, Tanmoy Chakraborty, and Akshay NambiPreprint, 2025Large language models (LLMs) have significantly improved their reasoning capabilities; however, they still struggle with complex multi-step mathematical problemsolving due to error propagation, lack of self-correction, and limited adaptability to diverse reasoning styles. Existing methods rely on static fine-tuning or prompt engineering, which fail to generalize across problem complexities, while the scarcity of high-quality preference data further hinders reliable reasoning. We introduce SPHERE, a self-evolving data generation pipeline that enhances reasoning in small language models (SLMs) by iteratively generating, correcting, and diversifying reasoning chains. SPHERE operates in three stages: (i) SelfGeneration, where the model autonomously constructs problem-solving steps; (ii) Self-Correction, enabling it to identify and rectify errors; and (iii) Diversity Induction, improving robustness through multiple valid reasoning trajectories. This self-evolution mechanism strengthens mathematical reasoning and enhances model reliability. Evaluations on MATH 500, GSM8K, AIME, AMC, and Olympiad show that SPHERE-trained models achieve significant gains over their base versions and match/surpass GPT-4o on certain benchmarks. Our findings demonstrate that selfevolving models can close the reasoning gap between SLMs and state-of-the-art LLMs, making mathematical AI more reliable, scalable, and efficient.
2024
-
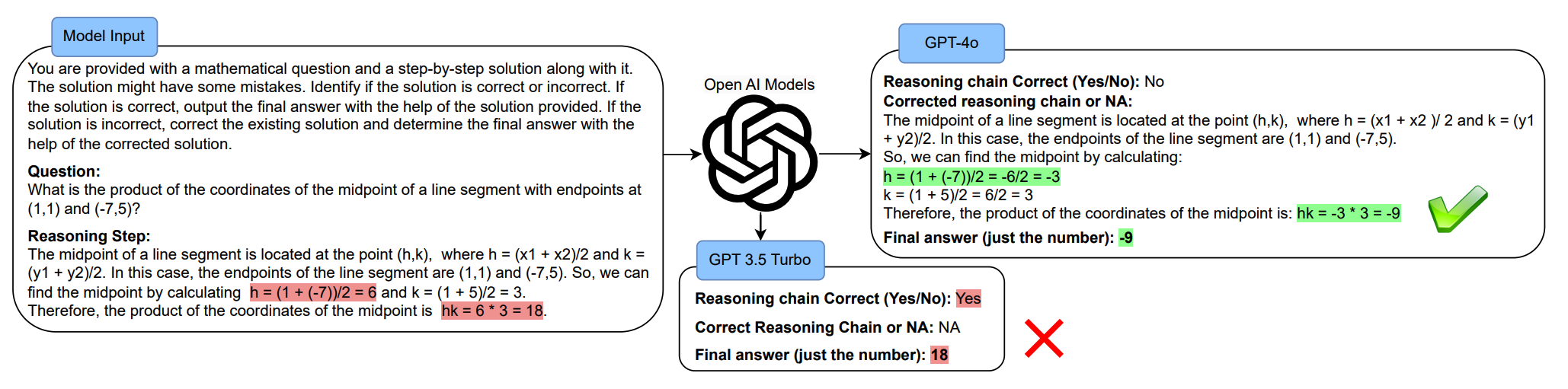 Exposing the Achilles’ Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical ReasoningJoykirat Singh, Akshay Nambi, and Vibhav Vineet2024
Exposing the Achilles’ Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical ReasoningJoykirat Singh, Akshay Nambi, and Vibhav Vineet2024Accepeted at ACL Main 2025
Large Language Models (LLMs) have transformed the approach to solving Math Word Problems (MWPs), especially in educational domains. However, current evaluations focus heavily on final answer accuracy, often neglecting the critical aspect of reasoning. This work addresses that gap by assessing LLMs’ abilities to detect and correct reasoning mistakes. We introduce a novel dataset, MWP-MISTAKE, which includes MWPs with both correct and incorrect reasoning steps generated via rule-based methods and smaller language models. Our benchmarking provides key insights into the strengths and weaknesses of state-of-the-art models, including closed-source, open-source, and fine-tuned variants. While GPT-4o consistently outperforms other models like GPT-4 , GPT-3.5Turbo , and smaller models, it still struggles to reliably detect mistakes across simple and complex problems. The significant performance drop on more challenging, unseen problems underscores the limitations of current LLMs in handling deeper reasoning tasks, revealing a need for improved generalization and robustness.14
-
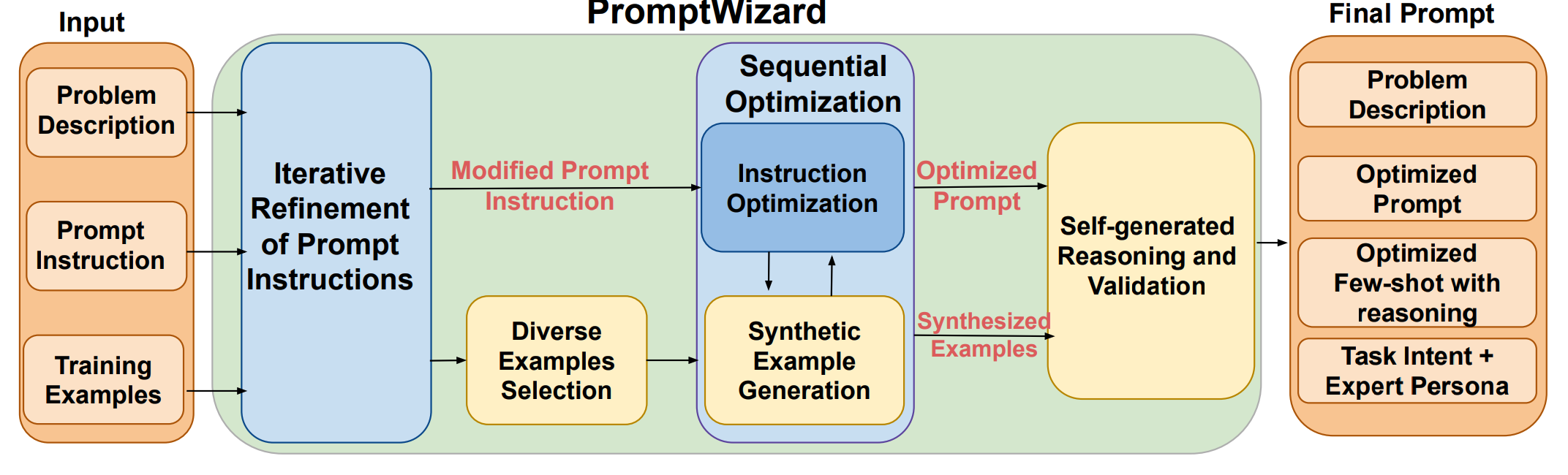 PromptWizard: Task-Aware Agent-driven Prompt Optimization FrameworkEshaan Agarwal, Joykirat Singh, Vivek Dani, and 3 more authors2024
PromptWizard: Task-Aware Agent-driven Prompt Optimization FrameworkEshaan Agarwal, Joykirat Singh, Vivek Dani, and 3 more authors2024Accepeted at ACL Findings 2025
Large language models (LLMs) have transformed AI across diverse domains, with prompting being central to their success in guiding model outputs. However, man- ual prompt engineering is both labor-intensive and domain-specific, necessitating the need for automated solutions. We introduce PromptWizard, a novel, fully automated framework for discrete prompt optimization, utilizing a self-evolving, self-adapting mechanism. Through a feedback-driven critique and synthesis pro- cess, PromptWizard achieves an effective balance between exploration and ex- ploitation, iteratively refining both prompt instructions and in-context examples to generate human-readable, task-specific prompts. This guided approach systemati- cally improves prompt quality, resulting in superior performance across 45 tasks. PromptWizard excels even with limited training data, smaller LLMs, and various LLM architectures. Additionally, our cost analysis reveals a substantial reduction in API calls, token usage, and overall cost, demonstrating PromptWizard’s efficiency, scalability, and advantages over existing prompt optimization strategies.
-
 Mechanistic Behavior Editing of Language ModelsJoykirat Singh*, Subhabrata Dutta*, and Tanmoy ChakrabortyPreprint, 2024
Mechanistic Behavior Editing of Language ModelsJoykirat Singh*, Subhabrata Dutta*, and Tanmoy ChakrabortyPreprint, 2024Accepeted at EMNLP Findings 2025
Large Language Models trained on web-scale text acquire language generation abilities that can solve a wide range of tasks, particularly when task knowledge is refined into the generative prior using in-context examples. However, spuri- ous features learned from noisy data hinder their generalizability. Supervised finetuning can introduce task specificity, but introduce data inefficiency. Prior studies indicate that (i) noisy neural circuitries coexist with generalizable ones within LLMs, and (ii) finetuning typically enhances (or suppresses) existing abil- ities without introducing newer ones. Building upon these, we propose TaRot, a novel method for task adaptation. TaRot intervenes in the neural circuitries using learnable rotation matrices that are optimized using Bayesian Optimiza- tion, on labelled samples in the order of standard few-shot prompting exam- ples. Experiments on multiple classification and generation tasks using LLMs of varying sizes reveal the efficacy of TaRot, improving upon both zero- as well as few-shot performance, with average improvements (across models and tasks) of 23.81% and 11.15%, respectively.
-
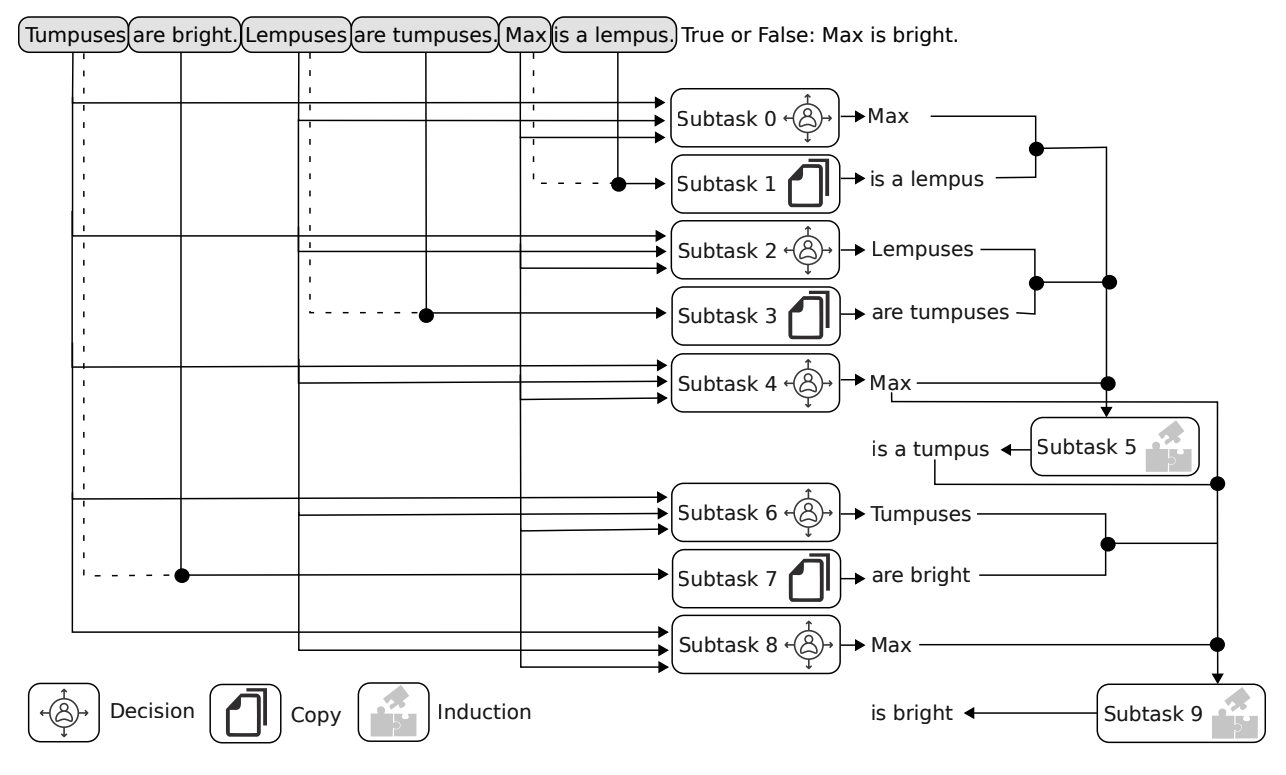 How to think step-by-step: A mechanistic understanding of chain-of-thought reasoningSubhabrata Dutta*, Joykirat Singh*, Soumen Chakrabarti, and 1 more author2024
How to think step-by-step: A mechanistic understanding of chain-of-thought reasoningSubhabrata Dutta*, Joykirat Singh*, Soumen Chakrabarti, and 1 more author2024Accepeted at TMLR Journal 2024
Despite superior reasoning prowess demonstrated by Large Language Models (LLMs) with Chain-of-Thought (CoT) prompting, a lack of understanding prevails around the internal mechanisms of the models that facilitate CoT generation. This work investigates the neural sub-structures within LLMs that manifest CoT reasoning from a mechanistic point of view. From an analysis of Llama-2 7B applied to multistep reasoning over fictional ontologies, we demonstrate that LLMs deploy multiple parallel pathways of answer generation for step-bystep reasoning. These parallel pathways provide sequential answers from the input question context as well as the generated CoT. We observe a functional rift in the middle layers of the LLM. Token representations in the initial half remain strongly biased towards the pretraining prior, with the in-context prior taking over in the later half. This internal phase shift manifests in different functional components: attention heads that write the answer token appear in the later half, attention heads that move information along ontological relationships appear in the initial half, and so on. To the best of our knowledge, this is the first attempt towards mechanistic investigation of CoT reasoning in LLMs.
-
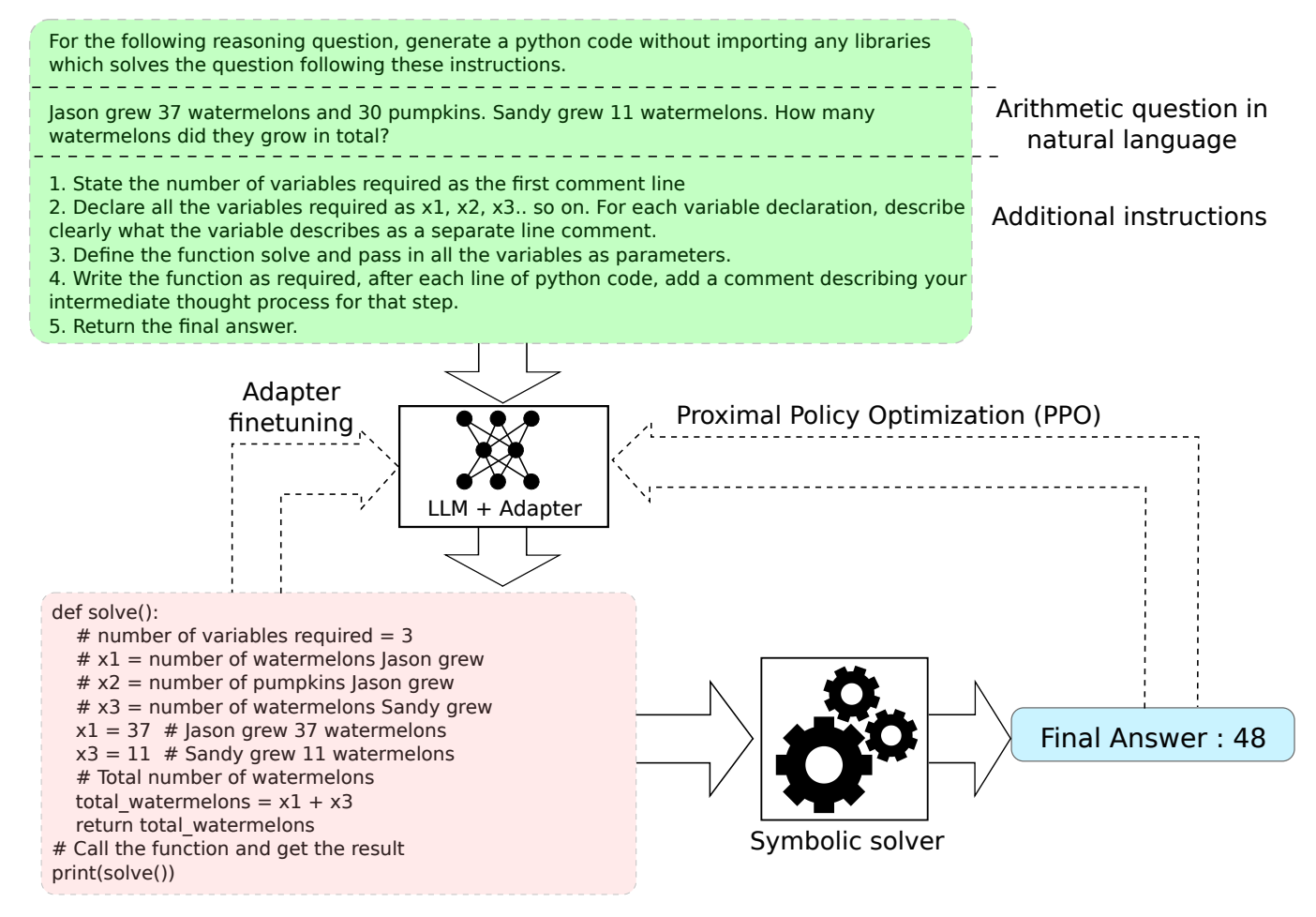 Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic ReasoningSubhabrata Dutta*, Joykirat Singh*, Ishan Pandey*, and 3 more authorsIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024
Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic ReasoningSubhabrata Dutta*, Joykirat Singh*, Ishan Pandey*, and 3 more authorsIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024Oral Presentation at AAAI’24
Large Language Models (LLM) exhibit zero-shot mathematical reasoning capacity as a behavior emergent with scale, commonly manifesting as chain-of-thoughts (CoT) reasoning. However, multiple empirical findings suggest that this prowess is exclusive to LLMs with exorbitant sizes (beyond 50 billion parameters). Meanwhile, educational neuroscientists suggest that symbolic algebraic manipulation be introduced around the same time as arithmetic word problems to modularize language-to-formulation, symbolic manipulation of the formulation, and endgame arithmetic. In this paper, we start with the hypothesis that much smaller LMs, which are weak at multi-step reasoning, can achieve reasonable arithmetic reasoning if arithmetic word problems are posed as a formalize-then-solve task. In our architecture, which we call SyReLM, the LM serves the role of a translator to map natural language arithmetic questions into a formal language (FL) description. A symbolic solver then evaluates the FL expression to obtain the answer. A small frozen LM, equipped with an efficient low-rank adapter, is capable of generating FL expressions that incorporate natural language descriptions of the arithmetic problem (e.g., variable names and their purposes, formal expressions combining variables, etc.). We adopt policy-gradient reinforcement learning to train the adapted LM, informed by the non-differentiable symbolic solver. This marks a sharp departure from the recent development in tool-augmented LLMs, in which the external tools (e.g., calculator, Web search, etc.) are essentially detached from the learning phase of the LM. SyReLM shows massive improvements (e.g., +30.65 absolute point improvement in accuracy on the SVAMP dataset using GPT-J 6B model) over base LMs, while keeping our testbed easy to diagnose, interpret and within reach of most researchers.
-
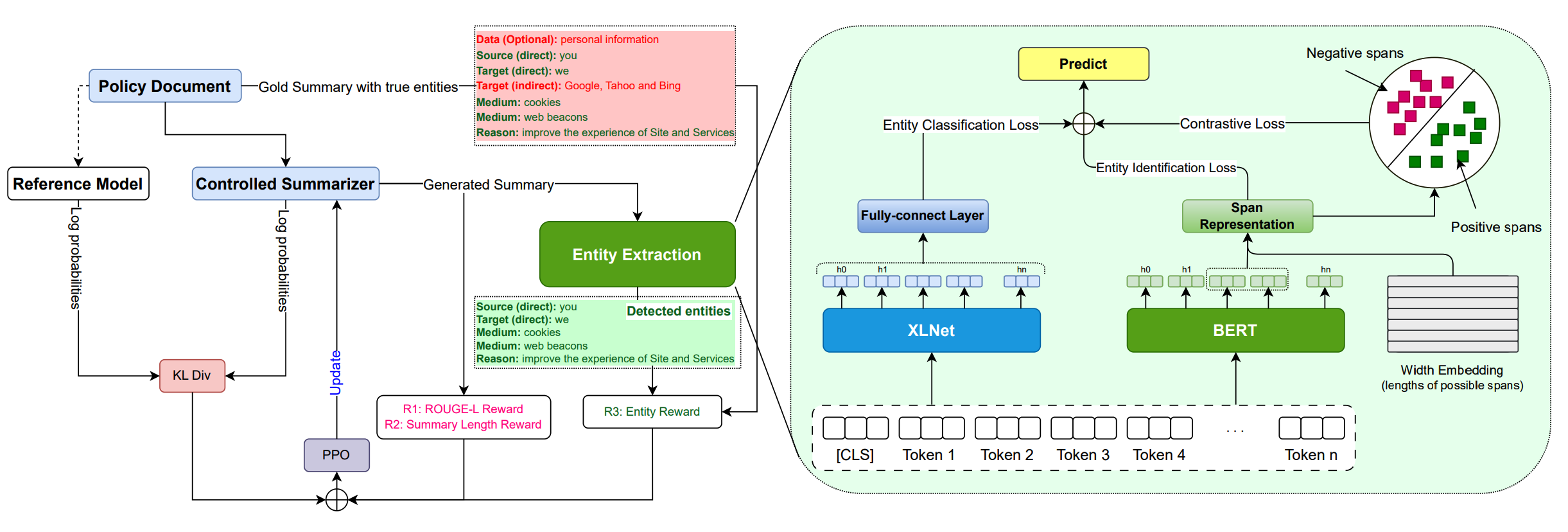 EROS: Entity-Driven Controlled Policy Document SummarizationJoykirat Singh*, Sehban Fazili*, Rohan Jain, and 1 more author2024
EROS: Entity-Driven Controlled Policy Document SummarizationJoykirat Singh*, Sehban Fazili*, Rohan Jain, and 1 more author2024Accepeted at LREC-COLING’24
Privacy policy documents have a crucial role in educating individuals about the collection, usage, and protection of users’ personal data by organizations. However, they are notorious for their lengthy, complex, and convoluted language especially involving privacy-related entities. Hence, they pose a significant challenge to users who attempt to comprehend organization’s data usage policy. In this paper, we propose to enhance the interpretability and readability of policy documents by using controlled abstractive summarization – we enforce the generated summaries to include critical privacy-related entities (e.g., data and medium) and organization’s rationale (e.g., target and reason) in collecting those entities. To achieve this, we develop PD-Sum, a policy-document summarization dataset with marked privacy-related entity labels. Our proposed model, EROS, identifies critical entities through a span-based entity extraction model and employs them to control the information content of the summaries using proximal policy optimization (PPO). Comparison shows encouraging improvement over various baselines. Furthermore, we furnish qualitative and human evaluations to establish the efficacy of EROS.